
Install Kafka Cluster With Zookeeper (Apache Kafka 3.x)
關於Kafka與Zookeeper
本站之前的文章曾經分享【在CentOS 7安裝Kafka單機版】,實際上,正式環境上若只是單機執行,風險非常大,有鑑於此,引入Zookeeper來實作高可用性,讓Kafka Cluster不僅能有多個節點同時運作,且保證資料一致性。
架構
此篇採用最少節點數,3台伺服器,來打造高可用性的Kafka Cluster,建議可以使用Rocky Linux【安裝Rocky Linux 8.x作為CentOS在企業級使用的後繼者】作為作業系統來完成後續的安裝,整體架構如下:
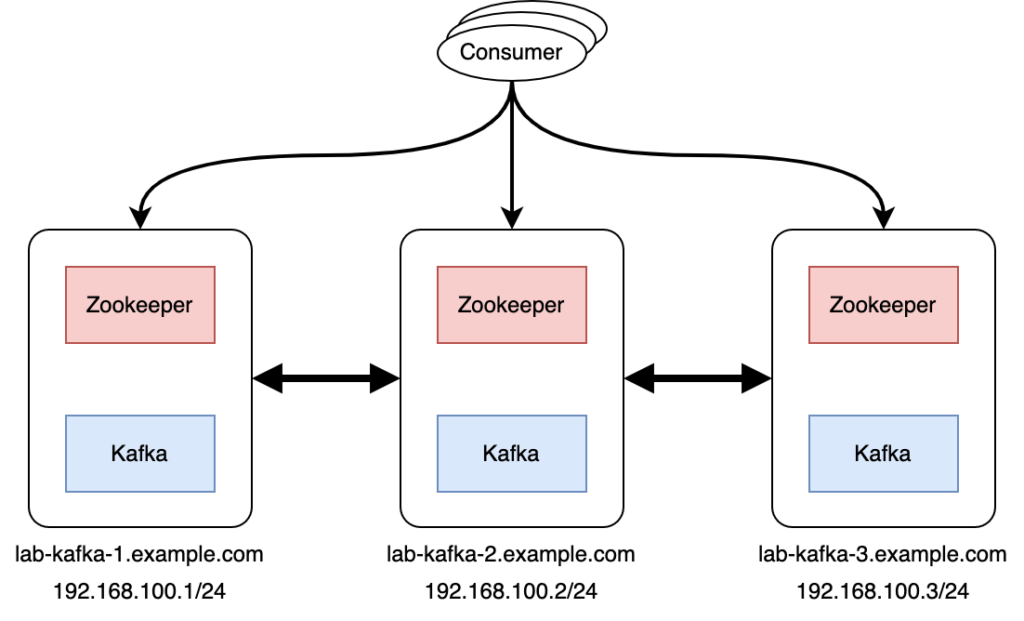
安裝前準備
【接下來每一個步驟在每一個節點都要做】
第1步:設定/etc/hosts檔案。(若環境有DNS Server則可以免設定)
$ sudo vi /etc/hosts
192.168.100.1 lab-kafka-1 lab-kafka-1.example.com
192.168.100.2 lab-kafka-2 lab-kafka-2.example.com
192.168.100.3 lab-kafka-3 lab-kafka-3.example.com第2步:安裝OpenJDK 11。
$ sudo yum install java-11-openjdk -y第3步:安裝wget用來下載安裝包。
$ sudo yum install wget -y第4步:於/opt下創建Kafka安裝的資料夾,就名為kafka。
$ sudo madir /opt/kafka第5步:下載Kafka執行檔安裝包(版本:2.13-3.1.0),並放置於/tmp裡。(各版本官方下載網址:連結)
$ cd /tmp
$ sudo wget https://dlcdn.apache.org/kafka/3.1.0/kafka_2.13-3.1.0.tgz第6步:解壓縮Kafka執行檔安裝包,並放置於/opt/kafka。
$ sudo tar zxvf kafka_2.13-3.1.0.tgz
$ sudo mv kafka_2.13-3.1.0/* /opt/kafka/第7步:創建名為kafka的使用者及群組,用於啟動Kafka與Zookeeper。
$ sudo adduser kafka第8步:創建Kafka與Zookeeper的檔案目錄。
$ sudo mkdir /opt/kafka/kafka_data
$ sudo mkdir /opt/kafka/zookeeper_data第9步:賦予資料夾”/opt/kafka”權限予使用者及群組:kafka。
$ shdo chown -R kafka:kafka /opt/kafka第10步:關閉防火牆。
$ sudo systemctl disable --now firewalld第11步:關閉SELinux。
$ sudo vi /etc/selinux/config
# SELINUX=enforcing
SELINUX=disalbed第12步:重新開機。
$ sudo reboot設定Zookeeper
【接下來每一個步驟在每一個節點都要做】
第1步:創建”myid”檔案於zookeeper的檔案目錄,用於分辨節點的ID。
$ sudo vi /opt/kafka/zookeeper_data/myid內容只要輸入數字即可,例如,第1個節點,myid內容就寫1,第2個節點,myid內容就寫2,以此類推…
第2步:調整Zookeeper的設定檔。
$ sudo vi /opt/kafka/config/zookeeper.properties
maxClientCnxns=0
tickTime=2000
initLimit=10
syncLimit=5
admin.enableServer=true
admin.serverPort=18080
dataDir=/opt/kafka/zookeeper_data
clientPort=2181
server.1=lab-kafka-1.example.com:2888:3888
server.2=lab-kafka-2.example.com:2888:3888
server.3=lab-kafka-3.example.com:2888:3888第3步:創建Zookeeper的systemd啟動檔案。
$ sudo vi /etc/systemd/system/zookeeper.service
[Unit]
Description=ZooKeeper Service
After=network-online.target
Requires=network-online.target
[Service]
Type=simple
Restart=on-failure
User=kafka
Group=kafka
ExecStart=/opt/kafka/bin/zookeeper-server-start.sh /opt/kafka/config/zookeeper.properties
ExecStop=/opt/kafka/bin/zookeeper-server-stop.sh /opt/kafka/config/zookeeper.properties
WorkingDirectory=/opt/kafka
[Install]
WantedBy=multi-user.target設定Kafka
【接下來每一個步驟在每一個節點都要做】
第1步:調整Kafka的設定檔。
$ sudo vi /opt/kafka/config/server.properties
# id請參考該節點的myid檔案內的數字,務必一樣!
broker.id=1
# 以下設定表示綁定所有網路,或可以另外指定hostname或IP來綁定網路。
listeners=PLAINTEXT://:9092第2步:創建Kafka的systemd啟動檔案。
$ sudo vi /etc/systemd/system/kafka.service
[Unit]
Description=kafka Service
After=network-online.target zookeeper.service
Requires=network-online.target
[Service]
Type=simple
Restart=on-failure
User=kafka
Group=kafka
ExecStart=/opt/kafka/bin/kafka-server-start.sh /opt/kafka/config/server.properties
ExecStop=/opt/kafka/bin/kafka-server-stop.sh /opt/kafka/config/server.properties
WorkingDirectory=/opt/kafka
[Install]
WantedBy=multi-user.target啟動Kafka Cluster
【接下來每一個步驟在每一個節點都要做】
第1步:重新載入systemd。
$ sudo systemctl daemon-reload第2步:啟動Zookeeper。
$ sudo systemctl enable --now zookeeper第3步:啟動Kafka。
$ sudo systemctl enable --now kafka~ END ~





